| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- llama-4
- Text-to-Image
- gemma2
- diffusion
- sfttrainer
- PEFT
- vLLM
- glibcxx
- transformer
- langchain
- torch._C._cuda_getDeviceCount()
- aimv2
- Mac
- nccl
- CPT
- ViT
- gemma-3
- multi-gpu
- Gemma
- gemma-3-27b-it
- tensor-parallel
- prompt
- error: mkl-service + intel(r)
- instruction tuning
- backbone
- Lora
- llm
- Fine-tuning
- ubuntu
- llama-4-scout-17b-16e-instruct
- Today
- Total
꾸준하게
[논문리뷰] Scalable Diffusion Models with Transformers (DiT) 본문
ICCV 2023 (Oral) Paper Page Code
William Peebles, Saining Xie
UC Berkeley, New York University
19 Dec 2022

Abstract
저자는 Transformer 아키텍쳐에 Diffusion을 접목하는 새로운 연구를 하였다. 기존 LDM(Latent Diffusion Model)에서의 U-Net 백본에 latent patch를 이용하는 Transformer를 접목한 것이다. 저자는 이것을 Diffusion Transformer (DiT)라 칭하며 다양한 확장성 또한 갖고있다고 한다. 결과적으로 저자가 제안한 (여러 크기 버전 중) DiT-XL/2 모델이 class-conditional ImageNet 512x512, 256x256 벤치마크에서 이전의 diffusion 모델을 능가하였으며 FID score 2.27를 달성하며 SOTA를 달성하였다.
Introduction
저자는 본 연구를 통해 Diffusion 모델에서 아키텍쳐 선택의 중요성을 밝히고 향후 생성 모델링 연구를 위한 경험적 기준선을 제시하고자 하였다. 저자는 U-Net의 Inductive bias가 Diffusion 모델의 성능에 중요하지 않을 수 있으며 Transformer와 같은 표준적인 디자인으로도 쉽게 대체할 수 있음을 보여주었다. 결과적으로, Diffusion 모델은 확장성, 견고성, 효율성과 같은 유리한 특성을 유지할 뿐만 아니라 다른 영역의 모범 사례와 학습 레시피를 상속하는 등 최근의 아키텍쳐 통합 추세의 이점을 누릴 수 있는 좋은 위치에 있다고 언급하였다.
본 논문에서는 Transformer를 활용한 새로운 Diffusion 모델인 Diffusion Transformer(DiT)를 제시한다. DiT는 기존의 Convolution(e.g. ResNet) 계열보다 시각적 인식에 더 효율적으로 확장할 수 있음을 확인한 Vision Transformer(ViT)를 참고하였다. 또한 저자는, 네트워크의 복잡성과 샘플의 품질에 따른 Transformer의 스케일링 결과를 연구하였다.
Diffusion Transformers
Diffusion Transformer Disign Space
Patchify. DiT에 대한 입력은 z로 표현된다(256 x 256 x 3 pixel space -> 32 x 32 x 4 latent space : z). DiT의 첫 Layer는 지spatial 정보가 담긴 이 z를 각 d 크기의 차원을 갖는 T개의 시퀀스 토큰으로 패치화하는 레이어로 시작된다(32 x 32 x 4 -> T x D). 이와함께 ViT와 마찬가지로 sine-cosine 값의 positional embeddings를 모든 입력 토큰에 적용한다. 이때, 토큰 수 T는 패치 사이즈를 결정하는 하이퍼파라미터 p에 의해 결정된다(
DiT block design. Diffusion 모델은 latent 외에도 noise timestep t, class label c, text embedding 등을 입력으로 받게된다. 저자는 다양한 입력을 받는 DiT block을 총 4가지 설계하였으며, ViT 표준으로부터 작지만 중요한 몇 가지 수정사항이 담겨있다.
- in-context conditioning. 벡터 임베딩 t와 c를 두 개의 추가적인 토큰으로 입력 시퀀스에 추가하여 이미지 토큰과 다르지 않도록 하였다. 이는 ViT의 cls 토큰과 유사하며 수정없이 기존의 ViT block을 사용할 수 있다. 마지막 block 후에는 입력 시퀀스로부터 conditioning 토큰을 제거하였다. 이 접근방식은 모델에 무시할만한 대한 새로운 Gflops를 도입한다.
- Cross-attention block. 저자는 t와 c 임베딩을 이미지 토큰 시퀀스와 별도로 길이가 2인 시퀀스로 concat하였다. Transformer block은 multi-head self-attention block에 이어 추가적으로 multi-head cross-attention을 포함하도록 수정되었으며 이는 class label에 대한 컨디셔닝을 위해 LDM에서 사용하는 것과 유사하다. Cross-attention은 모델에 가장 많은 Gflops를 추가하게 되며, 거의 15%의 오버헤드를 갖는다.
- Adaptive layer norm (adaLN) block. 저자는 GAN이나 U-Net을 사용하는 diffusion 모델들에서 폭넓게 사용되는 adaptive normalization layer를 기존 Transformer의 layer norm 대신에 넣는 것에 대해 실험하였다. 다이렉트로 차원 별 scale, shift 파라미터
γ β - adaLN-Zero block. ResNet에 대한 이전 연구에서 각 residual block을 identity function (항등함수; x=y) 으로 초기화하는 것이 효율적이라는 결과가 있었다. 예를들어, 각 block의 최종 batch norm에서 scale factor
γ γ β α α
Model size. 저자는 크기 d의 hidden 차원을 갖는 DiT block을 N개 쌓는 방식으로 모델 사이즈를 결정한다. ViT를 따라 표준 transformer config인 jointly scale N, d, attention heads 를 사용한다. 구체적으로, 다음 네 가지의 config를 사용한다. DiT-S, DiT-B, DiT-L, DiT-XL. 이들은 다양한 모델 사이즈와 0.3~118.6 규모의 Gflops를 갖게된다. 위 표에서 각 모델 별 config 값을 확인할 수 있다.
Transformer decoder. 마지막 DiT block 이후에는 이미지 토큰 시퀀스를 output noise prediction과 output diagonal covariance(대각 공분산) prediction으로 디코드해야한다. 이 각 출력값들은 original spatial input과 같은 shape을 가져야 한다. 저자는 표준 linear decoder를 사용하였다. 구체적으로, layer norm (만약 adaLN 사용중이라면 adaLN)과 linear 디코드를 각 토큰이 p x p x 2C 텐서로 변환되도록 한다 (C : DiT spatial input의 채널 수). 마지막으로, 디코딩된 토큰들을 예측된 노이즈와 공분산을 얻을 수 있도록 original spatial layout으로 rearrange한다.
Experimental Setup
DiT-XL/2 : XLarge config + patch size (p) = 2
Training.
- Dataset : ImageNet
- Resolution : 256 x 256, 512 x 512
- Initilaization : 마지막 linear layer는 zero-initialization, 나머지는 ViT에서 제안된 표준 초기화 방법
- Optimizer : AdamW
- learning rate : 1e-4 (no weight decay)
- batch size : 256
- augmentation : horizontal flip only
- exponential moving average (EMA) : 0.9999 (모든 벤치마크 결과는 EMA 버전 사용)
- etc : 그 외에는 ADM 설정을 따름
- c.f. : ViT와 달리 DiT 학습을 위해 warmup, reguliarization에 대한 필요성을 발견하지 못하였다고 함
Diffusion.
Pixel-space를 latent-space로 변환하기 위해 Stable Diffusion에 사용되는 pre-trained VAE를 사용하였다고 한다. 이때 downsampling factor=8로, resolution이 8배수만큼 작아지게 된다 (256 x 256 x 3 -> 32 x 32 x 4). 본 섹션의 실험에서 diffusion은 앞으로 이 latent space (z-space)에서 작동하게 된다. sampling 이후에는 VAE decoder를 이용하여 latent space를 pixel space로 변환한다. 실험 간 설정들은 ADM의 하이퍼파라미터를 준수한다. 구체적으로는 다음과 같음,
Evaluation metrics.
평가 메트릭으로는 generative 모델의 표준 평가지표인 Frechet Inception Distance (FID)를 사용하였다. 이전 연구들과의 비교를 위해 DDPM 250 sampling step을 갖으며 FID-50K에 대한 결과를 비교하였다. FID는 작은 구현 세부사항에 민감하다. 정확한 비교를 위해 [On aliased resizing and surprising subtleties in gan evaluation.] 논문에서 제안한 바와 같이 샘플을 추출하고 ADM의 평가를 활용한다. 이 외에도 Inception Score, sFID, Precision/Recall을 추가적인 평가 지표로 활용하였다.
Compute.
모든 모델은 JAX로 구현하였으며 TPU-v3 pods 환경에서 학습되었다. 가장 큰 모델인 DiT-XL/2은 초당 5.7 iters로, TPU-v3-256 pod에서 global batch size 256으로 학습되었다.
Experiments
DiT block design.
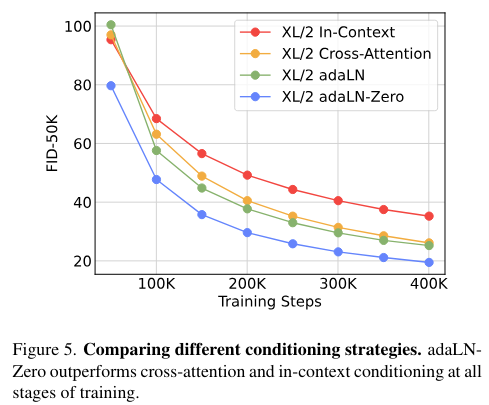
저자는 가장 큰 Gflops를 가지는 DiT-XL/2 모델에 대해 각기 다른 block 디자인을 적용해보았다.
- in-context : 119.4 Gflops
- cross-attention : 137.6 Gflops
- adaptive layer norm (adaLN) or adaLN-zero : 118.6 Gflops
실험 결과는 위 Figure 5.에서 보이는 바와 같이 adaLN-zero가 가장 좋은 성능을 보였다. 여기에서 알 수 있듯이 똑같은 adaLN이라도 zero-initialization을 사용하는 것에 대한 중요성을 알 수 있다. 이후 실험은 adaLN-zero DiT block을 기준으로 진행된다.
Scaling model size and patch size.
아래 그림은 모델 규모 및 패치사이즈에 대한 결과이다. 큰 모델 규모와 작은 패치 사이즈를 갖는 것이 성능이 가장 우수하다.

DiT Gflops are critical to improving performance.

위 Figure 6.를 보면 알 수 있듯이, 모델 규모 보다는 패치 사이즈의 변화가 성능 향상에 크게 기여하는 것을 알 수 있다. 패치 사이즈를 변화할 경우, 전체 파라미터 수는 변화가 없으며(아주 약간 감소) 오직 Gflops만 증가한다. 이에 대한 상관관계를 위 Figure 8.에 나타내었다. 상관계수가 -0.93으로, Gflops와 성능이 매우 강한 음의 상관관계를 갖고있다고 볼 수 있다. 즉, Gflops가 증가함에 따라 성능이 감소한다는 것은 매우 유의미하다는 것으로 나타났다.
Larger DiT models are more compute-efficient.

위 Figure 9.는 전체 학습 연산량 별 FID-50k 성능을 나타낸 것이다. 학습 연산량은 Gflips x batch size x training steps x 3으로 추정하였다(3은 backwards pass에 관한것으로, forward pass보다 2배 복잡한 연산을 가져 이렇게 근사치를 정하였다고 한다.). 저자는 실험을 통해 더 오래 학습된 작은 모델보다 적게 학습된 큰 모델이 더 높은 계산 효율성을 갖는다고 하였다. 마찬가지로 패치 사이즈를 제외하고는 동일한 모델이라도 다른 Gflops를 제어할 때에도 성능 프로필이 다르다는 것을 알 수 있다. (여기에서 논문에서는 약
Visualizing scaling.
아래 그림은 우측으로 갈 수록 모델 사이즈를 키운 것이고 하단으로 갈 수록 패치 사이즈를 줄인 것이다.

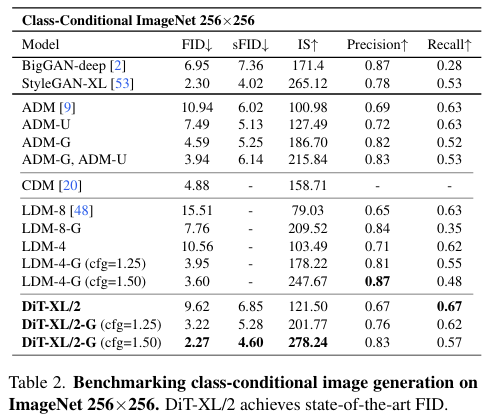
State-of-the-Art Diffusion Models
아래 표는 각 256x256, 512x512 ImageNet에 대한 결과로, 대부분의 평가지표에서 본 모델이 SOTA를 달성함.

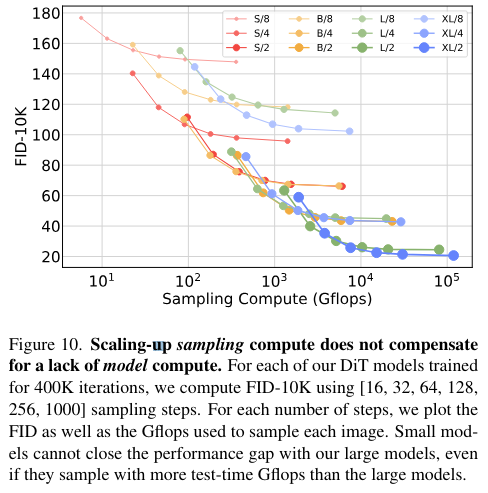
Scaling Model vs. Sampling Compute
Samping step 확장으로 작은 규모의 모델이 큰 규모의 모델을 능가할 수 있는 실험인데 그렇지 못한 것으로 나온다.