
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- llama-4-scout-17b-16e-instruct
- prompt
- sfttrainer
- Fine-tuning
- llama-4
- gemma-3
- langchain
- nccl
- gemma-3-27b-it
- error: mkl-service + intel(r)
- llm
- CPT
- instruction tuning
- Text-to-Image
- aimv2
- multi-gpu
- vLLM
- ViT
- Mac
- glibcxx
- PEFT
- tensor-parallel
- backbone
- ubuntu
- Gemma
- Lora
- transformer
- torch._C._cuda_getDeviceCount()
- diffusion
- gemma2
- Today
- Total
꾸준하게
[논문리뷰] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 본문
[논문리뷰] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
yeonsikc 2024. 5. 17. 19:47
arxiv 2022 paper
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou
Google Research, Brain Team
28 Jan 2022(v1)

Abstract
본 논문에서는 중간 추론 단계인 Chain-of-Thought(CoT)를 생성하는 것이 복잡한 추론을 수행하는 LLM의 능력을 어떻게 크게 향상시키는지 탐구하였다. 특히, 그러한 추론 능력이 충분히 큰 언어모델에서 어떻게 자연스럽게 나타나는지를 CoT라는 간단한 방법을 통해 보여준다. 3가지의 LLM에 대한 실험에서 CoT를 적용하는 것이 산수, 상식, 상징적 추론 작업의 성능을 향상시키는 것을 알 수 있었다.
Instroduction
NLP 분야에서 일반적으로 모델 규모를 키울 경우 대체로 성능이 좋아진다. 하지만 모델 규모를 확장하는 것만으로는 산술, 상식 및 기호 추론과 같은 까다로운 작업에서 높은 성능을 달성하는데 충분하지 않은 것으로 보인다.
본 논문에서는 두 가지 아이디어에 의해 동기 부여된 간단한 방법으로 대규모 언어 모델의 추론 능력을 어떻게 풀 수 있는지 탐구하였다.
- 산술 추론 기술은 최종 답을 도출하는 자연어 논리를 생성함으로써 이점을 얻을 수 있다.
- LLM은 프롬프트를 통한 in-context few-shot learning으로도 흥미로운 성능을 보인다.
하지만 위 아이디어들은 공통적인 핵심적인 한계가 있다. 일반적인 input-output paired ML Dataset과 달리, rationale-augmented 학습의 경우, 고품질의 근거를 대규모로 생성하는데 비용이 많이 든다. 본 논문에서는 <input, chain of thought, output> 의 삼중으로 구성된 프롬프트가 주어지면 추론 작업을 위한 few-shot 프롬프트를 수행할 수 있는 언어 모델의 능력을 탐구한다. 여기에서 chain of thought(생각의 사슬; 이하 CoT)는 최종 답변으로 이어지는 일련의 중간 자연어 추론 단계이다.
Chain-of-Thought Prompt
다단계 수학 단어 문제와 같은 복잡한 추론 과제를 풀 때 자신의 사고 과정을 고려한다. 예를들면, "A가 엄마한테 꽃을 2송이를 주고나니 10개가 남았다. 그 후, 아빠한테 3송이를 주었으니 남는 것은 총 7송이다." 본 논문의 목표는 언어 모델들에게 문제에 대한 최종 답으로 이어지는 일련의 일관된 중간 추론 단계인 유사한 사고를 생성할 수 있는 능력을 부여하는 것이다. 저자는 몇가지 예제에 대해 few-shot 프롬프트로 CoT 과정이 주어진다면 충분히 큰 언어 모델이 CoT를 생성할 수 있을것이라고 예상하였다.
이러한 CoT는 몇가지 매력적인 특징을 갖고 있다.
- CoT는 원칙적으로 모델이 multi-step 문제를 중간 단계롤 분해할 수 있도록 하는데, 이는 더 많은 추론 단계가 필요한 문제에 추가적인 계싼을 할당할 수 있음을 의미한다.
- CoT는 모델의 행동에 대해 해석할 수 있는 창구를 제공한다. 모델이 제안한 결과의 중간 과정을 알 수 있으며 잘못된 답변이 유도된 과정을 디버깅 할 수 있다.
- CoT는 수학 단어문제, 상식추론, 상징조작 등의 과제에 활용될 수 있으며, 인간이 언어를 통해 해결할 수 있는 모든 과제에 (적어도 원칙적으로) 잠재적으로 적용이 가능하다.
- CoT는 예시를 나타내는 few-shot 프롬프트를 포함하는것만으로 간단하고 효과적으로 다양한 LLM에 사용될 수 있다.
Arithmetic Reasoning
Experimental Setup
저자는 다양한 벤치마크와 다양한 언어모델로 CoT의 성능을 실험하였다.
Benchmarks
- GSM8K : 문장으로 표현된 수학 문제
- SVAMP : 다양한 구조를 가진 수학 단어 문제
- ASDiv : 다양한 수학 단어 문제
- AQuA : 대수가 포함된 수학 단어 문제
- MAWPS : 대수가 포함된 수학 단어 문제
Standard prompting
CoT를 사용하지 않은 베이스라인의 경우, in-context 상에서 입출력 쌍의 few-shot이 제공되는 방식으로 Brown et al. (2020)에서 제안된 방법을 사용한다. (본 포스트의 첫 이미지의 왼쪽 부분 참고)
Chain-of-thought prompting
CoT를 사용하는 경우, 답변을 유도하는 과정에 대해 few-shot prompt를 in-context에 포함시키는 방법이다. (본 포스트의 첫 이미지의 오른쪽 부분 참고)

저자는, 대부분 데이터 셋에서는 평가 분할만 있기 때문에 8개의 few-shot 예시 셋을 수동으로 구성했다. 객관식인 AQuA 데이터 셋을 제외한 나머지에서는 8개의 CoT few-shot set을 모두 사용하였다.

AQuA는 4가지 예시 및 솔루션을 사용하였다.(부록 표 21 참고)
Language models
- GPT-3 (Brown et al., 2020)
- InstructGPT(350M); text-ada-001
- InstructGPT(1.3B); text-baddage-001
- InstructGPT(6.7B); text-curie-001
- InstructGPT(175B); text-davinci-002
- LaMDA (Thoppilan et al., 2022) : 422M, 2B, 8B, 68B, 137B
- PaLM : 8B, 62B, 540B
- UL2 20B (Tay et al., 2022)
- Codex (Chen et al., 2021, code-davinci-002 in the OpenAI API)
저자는 greedy decoding을 통해 모델에서 샘플을 추출하였다고 한다. LaMDA의 경우, 5개의 무작위 seed에 대한 평균 결과를 보고하는데, 각 seed는 무작위로 섞인 예제의 순서가 서로 다르다. 또한 LaMDA 실험에서 서로 다른 seed 간에 큰 분산이 나타나지 않았기 때문에 계산을 절약하기 위해 다른 모델에 대한 단일 예시적인 주문에 대한 결과를 보고하였다.
Results
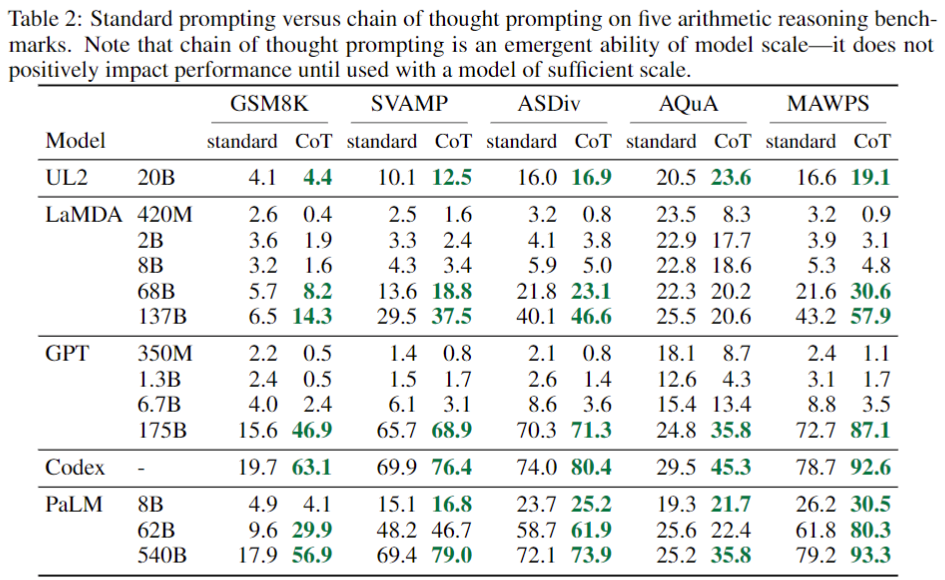
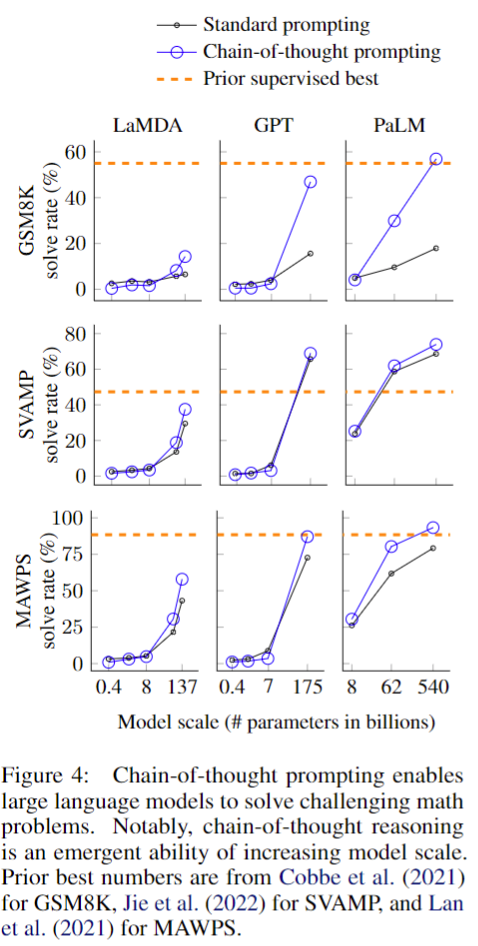
모델 종류, 모델 규모, 벤치마크 데이터셋에 대한 실험 결과는 위 테이블과 우측 그림에 요약되어 있다. 이 실험에는 세 가지 주요 시사점이 있다.
- 우측 그림에서 볼 수 있듯이, CoT는 모델 규모가 커질수록 효과가 커진다. 즉, CoT는 소형 모델에 긍정적인 영향을 미치지 않으며, ~100B 모델과 함께 사용할 경우 성능이 상승한다. 저자는 더 작은 규모의 모델이 비교적 유창하지만 비논리적인 사고 사슬을 생성하여 표준 프롬프트보다 성능이 낮다는 것을 정성적으로 확인하였다고 한다.
- CoT 프롬프트는 더 복잡한 문제에 대해 더 높은 성능 향상을 달성한다. 예를들어, GSM8K(베이스라인 점수가 가장 낮은 데이터 셋)의 경우, 가장 큰 GPT 및 PaLM 모델의 경우 성능이 두 배 이상 향상되었다. 반면에, SingleOp(MAWPS의 쉬운 서브셋으로, 답변에 single-step만 요구됨)에서는 성능이 나빠지거나 미약하게 좋아지는데 그쳤다. (Appendix Table 3 참고)
- GPT-3(175B)와 PaLM(540B) 모델을 통한 CoT 프롬프팅은 기존의 Prior supervised best 모델(SOTA)이 labeld dataset에 대해 fine-tuned task-specific model인 것에 견주어 볼 때, 유리한 비교가 가능하다.(우측 그림의 주황점선보다 CoT가 높거나 비슷하다 -> 별도의 튜닝없이 SFT를 능가).
Ablation Study
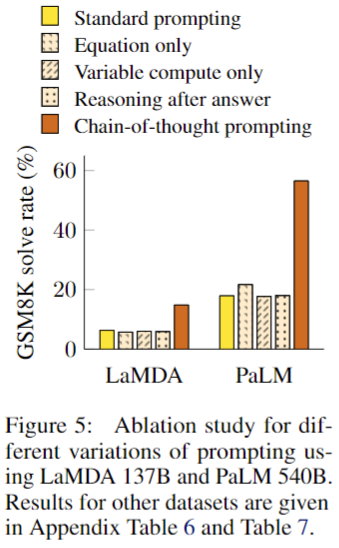
CoT를 사용하는 것의 관찰된 이점은 다른 유형의 프롬프트를 통해 동일한 성능 향상을 부여할 수 있는지에 대한 자연스러운 질문을 제기한다. 이에, 다양한 유형읠 프롬프트에 대한 실험을 진행하였다.
- Equation only : 모델이 답을 내놓기 이전에 수학 방정식만 출력하도록 유도하는 방식. 이는 GSM8K에서 성능 향상에 도움이 되지 않았는데, 저자는 본 데이터 셋이 자연어 없이 단번에 방정식으로 변환하는 것이 어려웠기 때문이라고 주장한다.
- Variable compute only : 문제 해결에 필요한 방성식의 문자 수와 동일한 점(dot; ...)의 시퀀스만 출력하는 방식. 베이스라인과 유사한 성능을 보였으며 이는 변수 계산 자체가 CoT의 성공 이유가 아닌, 자연어를 통해 중간 단계를 표현하는 것이 유용하다는 것을 시사한다.
- Chain of thought after answer : 모델이 실제로 생성된 사고 CoT에 의존하여 최종 답변을 제공하는지 여부를 분리하여 답변 후에만 CoT가 제공되는 대안 구성을 테스트. 베이스라인과 유사한 성능을 보였으며, 이는 CoT에 구현된 순차적 추론이 단순히 지식을 활성화하는 것 이상의 이유로 유용하다는 것을 시사한다.
Robustness of Chain of Thought

예시에 대한 민감도는 프롬프트 접근 방식의 핵심 고려 사항이다. 예를 들어, 예시 순열을 변경하면 GPT-3 onSST-2의 정확도가 우연에 가까운 수준(54.3%)에서 최첨단 수준에 가까운 수준(93.4%)까지 다양해질 수 있다(Zhao et al., 2021). 마지막 하위 섹션에서는 다양한 주석자가 작성한 CoT에 대한 견고성을 평가한다. 주석자 A가 작성한 CoT를 사용한 위의 결과 외에도, 이 논문의 다른 두 공동 저자(주석자 B와 C)는 동일한 몇 장의 예시에 대해 독립적으로 CoT를 작성했다(부록 H에 표시). 주석자 A는 또한 Cobbe et al. (2021)에 제시된 해법 스타일을 따라 원본보다 더 간결한 또 다른 CoT를 작성했다.
우측 그림은 LaMDA 137B 모델에 적용한 결과이다. CoT 간의 분산은 있지만 이들 모두 다른 방식보다 큰 격차의 좋은 결과를 보였다. 이 결과는 CoT를 성공적으로 사용하는 것이 특정 언어적 스타일에 의존하지 않는다는 것을 의미한다.
Commonsense Reasoning
CoT는 특히 수학 단어 문제에 적합하지만, 언어 기반 연쇄 사고의 특성상 일반적인 배경 지식을 전제로 물리적 및 인간 상호 작용에 대한 추론을 포함하는 광범위한 종류의 상식 추론 문제에도 적용할 수 있다. 상식 추론은 세상과 상호작용하는데 있어 핵심적인 요소이며 현재의 자연어 이해 시스템으로도 아직 도달할 수 없는 영역이다.(Talmor et al., 2021)
Benchmarks
- CSQA (Talmor et al., 2019) : 종종 사전 지식이 필요한 복잡한 의미론과 관련된 세상에 대한 상식적인 질답셋
- StrategyQA (Geva et al., 2021) : 질문에 답하기 위해 멀티홉(multi-hop) 전략을 추론하는 모델을 요구. 주어진 문맥에서 날짜를 추론하는 날짜 이해와 스포츠와 관련된 문장이 그럴듯한지 아닌지를 판단하는 스포츠 이해라는 두 가지 전문 평가 셋을 선택(BIG-bench collaboration, 2021).
- SyaCan (Ahn et al., 2022) 자연어 명령어를 이산 집합의 로봇 동작 시퀀스에 매핑
그림 참고
Prompts
전반적으로 이전 섹션과 동일한 실험 설정을 따른다. CSQA와 StrategyQA의 경우, 학습 셋에서 무작위로 예시를 선택하고 이를 위한 CoT를 수동으로 구성하여 few-shot 예시로 사용하였다. 두개의 BIG-bench 태스크에는 학습 셋이 없으므로 평가셋에서 첫 10개의 예시를 few-shot 예시로 선택하고 나머지 평가 셋에는 보고서 번호를 지정했다. SayCan의 경우, Ahn et al.(2022)등에서 사용된 학습 셋의 6개 예제와 수동으로 구성한 CoT를 사용했다.
Results
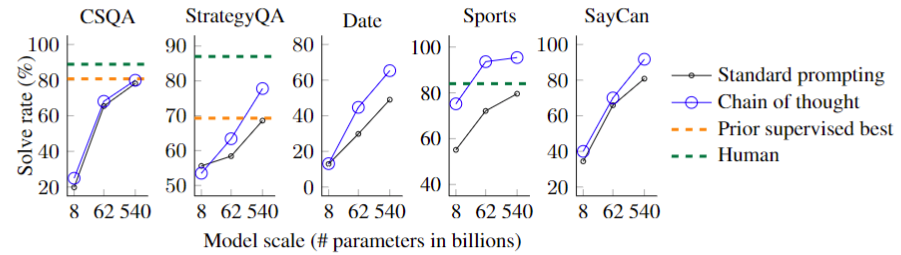
위 그림은 PaLM에 대한 이러한 결과를 강조한다. 모든 작업에서 모델 크기를 확장하면 Standard prompting의 성능이 향상되었으며, CoT는 이보다 더 향상되었으며 PaLM 540B의 경우 개선 효과가 가장 큰 것으로 나타났다. CoT를 통해 PaLM 540B는 StrategyQA(75.6 v.s. 69.4%)에서 이전 SoTA를 능가하고 스포츠 이해(95.4% v.s. 84%)에서 비전문가보다 더 나은 성능을 보여 기준선 대비 강력한 성능을 달성하였다. 이러한 결과는 CoT 프롬프트가 다양한 상식적 추론 능력을 요구하는 작업에서도 성능을 향상시킬 수 있음을 보여준다.(단, CSQA에서는 성능 향상이 미비했다.)
Symbolic Reasoning
마지막 실험에서는 인간에게는 간단하지만 언어모델에게는 잠재적으로 길어질 수 있는 상징적 추론을 고려하였다고 한다. CoT 프롬프팅이 언어 모델이 표준 프롬프팅에서는 어려운 상징적 추론 작업을 수행할 수 있을 뿐만 아니라 few-shot으로 구성된 예시보다 더 긴 추론 시간 입력에 대한 길이 일반화도 용이하다는 것을 보여주었다.
Task 1. Last letter concatenation
이 태스크는 모델에게 이름의 마지막 글자를 연결하도록 요청하는 것이다.(예 : "Amy Brown" -> "yn") 이는, 이미 모델이 CoT 없이 수행했던 앞글자를 따는 것보다 더 어려운 버전이다. 저자는 센서스 데이터에서 상위 1,000개의 이름과 성을 무작위로 연결하여 전체 이름을 생성하였다고 한다.
Task 2. Coin flip
이 태크스는 사람들이 동전을 뒤집거나 뒤집지 않은 후에도 동전히 여전히 앞면인지 아닌지를 대답하도록 모델에 요청하는 것이다.(예 : "동전이 앞면입니다. A가 동전을 뒤집었습니다. B는 동전을 뒤집지 않았습니다. 코인이 앞면인가요? -> "아니요")
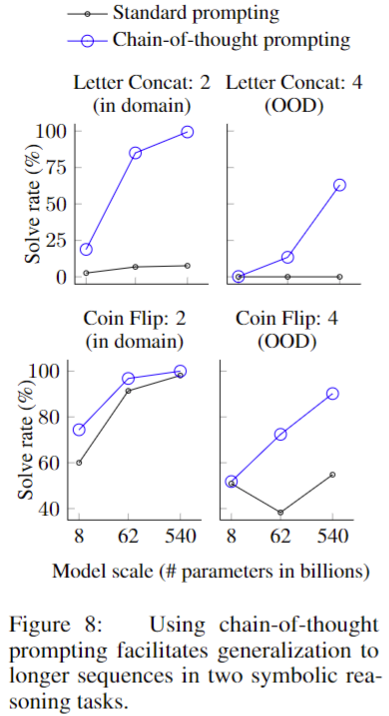
이러한 기호 추론 과제의 구성이 잘 정의되어 있기 때문에 각 과제에 대해 예제의 각 태스크에 대해 예제의 step 수가 학습/few-shot 예제와 동일한 in-domain 테스트 데이터와 평가 예제의 단계 수가 예제보다 많은 out-of-domain(ODO) 테스트 셋을 고려하였다.
Results
PaLM 540B의 경우, in-domain에서 100%에 가까운 해결률을 보였다. 저자는 이러한 in-domain 평가는 이미 few-shot을 통해 제공된다는 점에서 toy task이며 모델이 해야할 일은 테스트 예제의 새로운 기호로 동일한 단계를 반복하는 것뿐이라는 점에 유의해야한다고 강조하였다. 하지만 작은 모델에서는 여전히 좋지 못한 결과를 보인다. 보이지 않는 기호를 추상적으로 조작하는 능력은 100B 규모의 모델에서만 가능한 것으로 결론내려진다.
OOD에서 베이스라인은 두 태스크 모두 실패하지만 CoT를 사용한 경우, 모델 규모에 따라 상승 곡선을 보이고 있다. 따라서 CoT 프롬프팅은 충분한 규모의 언어 모델에 대해 CoT의 few-shot 예시와 다르게 길이 일반화를 용이하게 한다고 결론내릴 수 있게된다.
Conclusions
본 논문에서는 LLM의 in-context에 few-shot의 CoT를 적용하여 간단하면서도 효과적이고 광범위하게 사용되는 방법을 제안하였다. 산술적, 상징적, 상식적 추론에 대한 실험을 통해 모델 규모가 충분히 큰 언어모델에서도 수행할 수 있다는 사실을 발견할 수 있었다.



