
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- instruct pre-training
- cross-document attention
- Text-to-Image
- instruction tuning (it)
- gemma2
- instruct-pt
- Mac
- domain-adapted pre-training
- langchain
- Fine-tuning
- PEFT
- lora+
- continued pre-training
- transformer
- Lora
- diffusion
- instruction tuning
- ViT
- llm tuning
- full fine-tuning (fft)
- llm
- sfttrainer
- continued pre-train (cpt)
- prompt
- backbone
- CPT
- continual pre-training
- ubuntu
- error: mkl-service + intel(r)
- glibcxx
- Today
- Total
꾸준하게
[논문리뷰] InstantStyle: Free Lunch towards Style-Preserving in Text-to-Image Generation 본문
[논문리뷰] InstantStyle: Free Lunch towards Style-Preserving in Text-to-Image Generation
yeonsikc 2024. 5. 3. 16:32
arXiv paper code
Haofan Wang, Qixun Wang, Xu Bai, Zekui Qin, Anthony Chen
InstantX Team
3 Apr 2024

Abstract
별도의 학습 없이 레퍼런스 이미지를 활용한 diffusion 모델은 개인화 및 커스터마이징에 상당한 잠재력을 보이고 있다. 하지만, 모델이 스타일이 일관된 이미지를 생성하는 데 있어 몇 가지 복잡한 문제와 계속 씨름하고 있다.
- 스타일이라는 개념은 본질적으로 색상, 소재, 분위기, 디자인, 구조 등 다양한 요소를 포괄하는 포괄적인 개념이다.
- Inversion 방식은 스타일이 저하되기 쉬우므로 세밀한 디테일이 손실되는 경우가 많다.
- adapter 방식은 스타일 강도와 텍스트 제어 가능성 사이의 균형을 맞추기 위해 각 레퍼런스 이미지에 대해 세심한 가중치 필요한 경우가 많다.
본 논문에서는 몇 가지 설득력 있지만 흔히 간과되는 관찰 결과를 살펴보는 것으로 시작한다. 그 다음으로, 이러한 이슈들을 해결하기 위해 다음 두 가지 전략이 구현된 InstantStyle을 제안한다.
- 동일한 공간 내의 feature는 서로 덧셈이나 뺄셈이 가능할 것이라고 가정하여 Feature 공간 내의 레퍼런스 이미지에서 스타일과 콘텐츠를 분해하는 간단한 메커니즘을 구현.
- 레퍼런스 이미지 feature를 스타일별 블록에만 주입하면 스타일 누수를 방지하고, 파라미터가 많은 디자인의 특징인 번거로운 웨이트 튜닝을 피할 수 있다.
Methods
Motivation

스타일 정의는 아직 결정되지 않았다.
ID consistency generation와 같은 이전의 일관성 태스크에서는 생성된 얼굴들의 유사성을 비교하여 품질을 측정할 수 있고 다양한 평가 지표가 존재한다. 이러한 정량적 지표가 충실도를 완벽하게 나타내는 것은 아니지만, 적어도 user study를 통해 측정할 수 있다. 그러나 스타일 일관성을 위해서는 이러한 평가지표가 부족하다. 여기에서 핵심은 이미지의 스타일에 통합된 정의가 없다는 것이다. 다른 장면에서, 스타일의 의미는 상당히 다르다. 예를 들어, 중국 동양화에서는 잉크, 수채화나 오일 페인팅과 같은 색소 이 외에도 레이아웃, 소재, 분위기 등이 스타일이 될 수 있다. 스타일은 보통 하나의 요소가 아닌 여러 복잡한 요소의 조합이다. 따라서 스타일에 대한 정의는 상대적으로 주관적인 문제이며, 동일한 스타일에 대해 여러 가지 합리적인 해석이 존재할 수 있다.
그 결과, 동일한 스타일의 대규모 데이터를 수집하는 것은 매우 어렵다. 물론, 상황 설명을 통한 LLM 연구와, 비공개 소스의 T2I 생성 모델인 미드저니와 같은 이전의 연구들이 있지만 이들은 다양한 문제를 갖고있다.
- 원래 생성된 데이터에 노이즈가 많고, 세분화된 스타일을 구별하는 것은 어렵기 때문에 정제가 상당히 어렵다.
- 보다 세밀한 스타일은 텍스트 등으로 설명할 수 없기 때문에 스타일 수는 보통 제한된다.
Inversion에 의한 스타일 성능 저하

inversion 방식은 레퍼런스 이미지와 텍스트가 주어지면, 이미지에 DDIM inversion 기법을 적용하여 반전된 diffusion 궤적인 $x_T, X_{T-1},\ ..., x_0$을 얻고, inversion 방정식을 근사화하여 이미지를 잠재 노이즈 표현으로 변환한다. 그런 다음, $X_t$와 새로운 프롬프트 셋에서 시작하여 입력에 맞춰 정렬된 스타일로 새 콘텐츠를 생성한다. 그러나 위 이미지에서 볼 수 있듯이, 실제 이미지에 대한 DDIM inversion은 로컬 선형화 가정에 의존하기 때문에 불안정하며, 이로 인해 오류가 전파되어 잘못된 이미지 재구성 및 콘텐츠 손실로 이어질 수 있다. 직관적으로, 텍스쳐나 재질과 등과 같은 많은 세밀한 스타일 정보를 잃는 것을 볼 수 있다. 이 경우, 스타일을 잃은 사진을 guidance condition으로 사용하면 스타일을 효과적으로 전송할 수 없다. 또한, inversion 프로세스는 추론 파라미터에 민감하기 때문에 생성 속도가 매우 느려진다. (원하는 결과를 갖기 위해 파라미터를 바꾸어가며 다양하게 추론해보아야 하므로)
스타일 강도와 콘텐츠 누수 간의 Trade-off
선행 연구들에서 볼 수 있듯이, 스타일 조건 주입에도 균형이 있다. 만약 이미지 조건의 강도가 너무 높다면 콘텐츠들은 많이 누수될 것이고, 반대로 너무 낮다면 스타일이 충분히 반영되지 않을 것이다. 이것에 대한 핵심적인 이유는, 이미지 안에 스타일과 콘텐츠가 결합되어 있기 때문이며, 위에서 언급한 스타일의 속성이 명확하지 않기 때문에 이 둘 (스타일, 콘텐츠) 을 분리하기 어려운 경우가 많다. 그러므로, 각 레퍼런스 이미지에 대해 스타일 강도와 프롬프트 간의 밸런스를 꼼꼼하게 튜닝해야 한다.
Observations

Adapter의 기능은 과소평가되었다.
흥미롭게도, 저자는 이전의 연구들에서 IP-Adapter의 스타일 트랜스퍼 능력에 대한 평가가 편향되었다는 것을 발견했다고 주장한다. 그중 일부는, 고정 매개변수를 사용하여 IP-Adapter의 텍스트 제어 기능이 약하다고 주장하고 있고, 다른 일부는 콘텐츠 누수 문제를 강조하였다고 한다. 이들은 적절한 강도를 설정하지 않았다는 같은 이유로 발생한 것으로 보인다. IP-Adapter는 Cross Attention에서 K와 V를 각각 텍스트와 이미지로 사용하고 마지막에 linear weighting(선형 가중치)를 수행하기 때문에, 너무 높은 강도는 필연적으로 텍스트의 제어력이 떨어질 수밖에 없다. 동시에 이미지의 콘텐츠와 스타일이 분리되지 않기 때문에 콘텐츠 누수 문제가 발생한다. 가장 간단하고 효과적인 방법은 낮은 강도를 사용하는 것이며, 이렇게 함으로써 저자는 대부분의 연구에서 언급된 문제가 해결된다는 것을 발견했지만 강도를 조정하는 것이 매우 까다롭고 항상 작동하지 않다는 것에 동의한다고 한다.
CLIP 임베딩을 분리된 표현으로 뺀다.

CLIP 모델은 contrastive loss를 통해 이미지와 텍스트가 같은 임베딩 공간에 매핑되도록 하며 매우 큰 weakly-aligned text-image pair에서 학습되었다. 이전 대부분의 Adapter 방식의 연구들은 주어진 이미지의 feature를 추출하기 위해 pre-trained CLIP image encoder를 사용하였다. 이러한 연구 중에는, CLIP image encoder로부터 얻어지는 이미지 임베딩은 전체적인 콘텐츠와 스타일을 담을 수 있다고 한다. 비록 위에서 언급한 대로 스타일 강도를 낮춤으로써 콘텐츠 누수와 같은 문제들이 해소될 수는 있지만, 여전히 일부 경우 콘텐츠와 스타일 결합 문제가 발생한다. (콘텐츠와 스타일 요소를 분해할 수 없음을 언급) 이전에도 스타일과 콘텐츠의 표현을 각각 추출하기 위해 쌍을 이루는 스타일 데이터 셋을 구성하는 작업이 있었지만, 스타일의 다양성으로 인해 한계가 있었다. 사실, image retrieval에서 영감을 얻은 간단하면서도 효율적인 방법이 있다. CLIP의 feature space는 좋은 호환성을 갖고 있으며, 같은 feature space에서의 feature를 더하거나 빼는 게 가능하다. 사실 답은 뻔하다. 사진에는 콘텐츠와 스타일 정보가 모두 포함되어 있고 스타일에 비해 콘텐츠는 텍스트로 설명할 수 있는 경우가 많으므로, 새로운 featrue가 여전히 CLIP space에 있다고 가정하면 사진 feature에서 콘텐츠 부분을 명시적으로 제거할 수 있다.
각 블록들의 영향은 동일하지 않다.

CNN의 시대의 많은 연구들에서 얕은 convolution layer는 형태, 색상과 같은 낮은 레벨의 표현력을 학습하고, 깊은 layer에서는 의미론적 정보에 집중한다는 것을 발견하였다. Diffusion 모델에서도 같은 로직이 존재한다. 텍스트 조건과 이미지 조건은 일반적으로 Cross Attention Layer를 통해 모델에 주입된다. 저자는 Attention layer마다 스타일 정보를 포착하는 것이 다르다는 것을 발견했다고 한다. 위 이미지에서 볼 수 있듯이, 저자는 스타일을 표현하는 두 개의 특별한 layer를 발견하였다. (SDXL + IP-Adapter에서) up_blocks.0.attentions.1과 down_blocks.2.attentions.1은 각각 스타일(색상, 재질, 분위기)과 공간적 레이아웃(구조, 위치)을 포착하며, 스타일 요소로서 레이아웃을 고려하는 것은 주관적이며 개인마다 다를 수 있다. up_blocks.0.attentions.1은 스타일을 포착하므로 필수이지만, down_blocks.2.attentions.1은 위치를 포착하는 것이므로 선택사항임)
Methodology
본 섹션에서는, 위 섹션에서 언급한 관측들에 근거하여 콘텐츠와 스타일을 간단하면서도 효율적으로 분해하는 방법 두 가지를 소개한다. 이들은 서로 영향을 끼치지 않으며 다른 모델에 개별적으로 Free-Launch처럼 원활하게 사용할 수 있다.
이미지로부터 콘텐츠를 분리
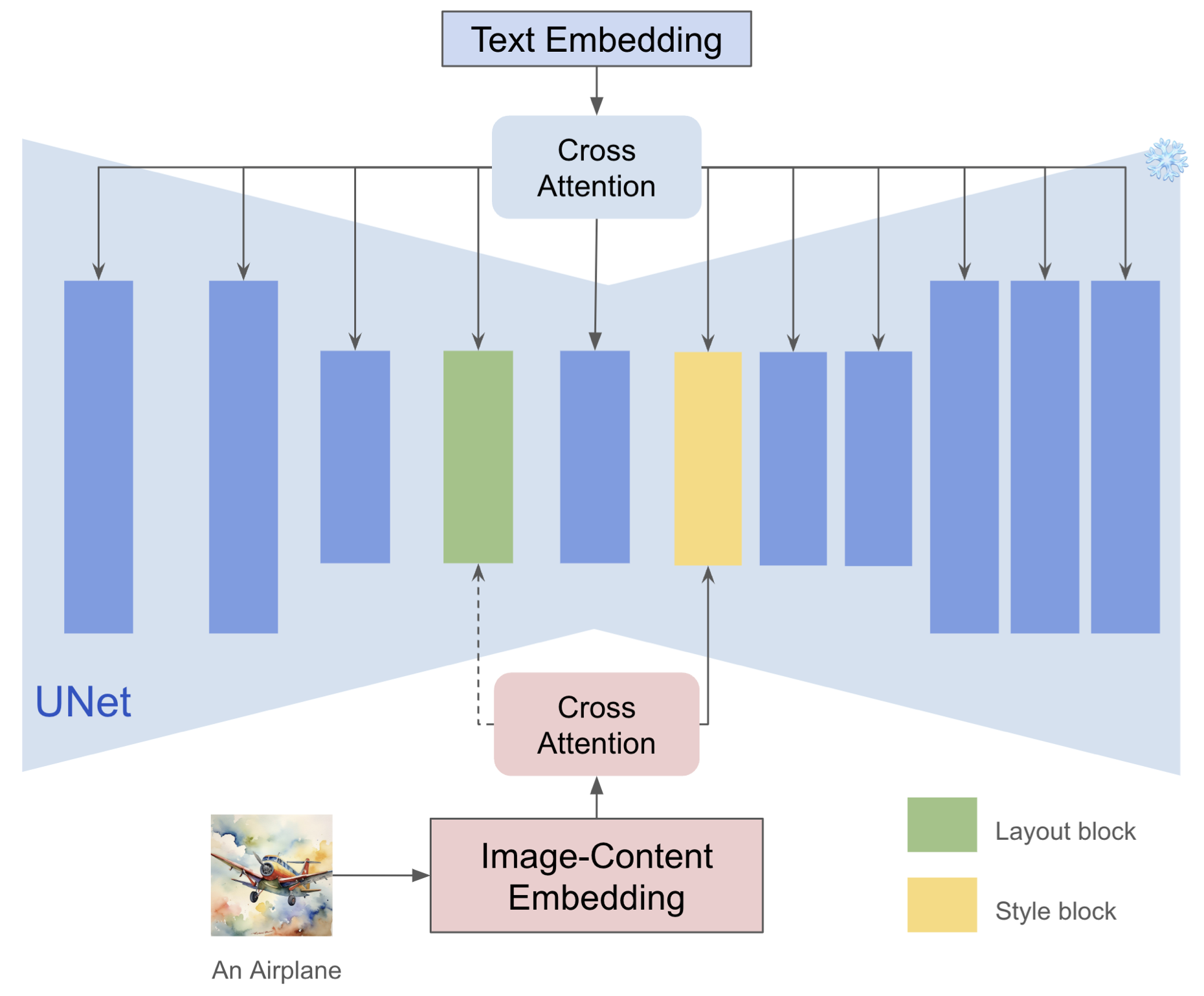
정의하기 어려운 스타일과 달리, 콘텐츠는 자연어로 표현될 수 있다. 더욱이, CLIP text encoder를 통해 텍스트를 featrue space로 추출할 수도 있다. 동시에, CLIP image encoder를 사용하여 레퍼런스 이미지의 feature를 추출할 수도 있다. 이미지 feature에서 텍스트 feature를 빼고 나면 스타일과 콘텐츠를 명시적으로 분리할 수 있는 CLIP global feature의 장점을 활용할 수 있다. 비록 간단하지만 이 전략은 매우 효과적이며 콘텐츠가 누수되는 것을 완화시켜 준다.
스타일 블록에만 주입
경험적으로 알 수 있듯이, Deep network의 각 레이어는 서로 다른 의미론적 정보를 포착한다. 저자는 본 논문에서 스타일과 콘텐츠를 분리하는 방법을 제안하였으며 레이아웃과 스타일을 포착하는 블록을 발견하였다. 이를 통해 스타일 정보를 암시적으로 추출하여 스타일의 강도를 잃지 않으면서 콘텐츠 누수를 방지할 수 있다. 직관적으로, 스타일 정보를 스타일을 포착하는 블록에 주입하기만 하면 된다. 또한, Adapter의 파라미터 수가 크게 줄기 때문에 텍스트 제어 기능도 향상된다. 저자는 이 메커니즘은 편집이나 기타 작업을 위한 다른 Attention 기반의 feature 주입에도 적용할 수 있다고 주장한다.
Experiments
저자는 SDXL과 pre-trained IP-Adapter를 사용하였으며 스타일 블록을 제외한 블록은 비활성화하였다. 4M 규모의 Text-image paired 데이터 셋을 사용하였으며 하이퍼 파라미터는 official setting을 사용하였으나 모든 블록을 학습하지는 않았다.(스타일 블록만 학습)
텍스트 기반 이미지 생성
아래 실험 결과들은, 한 장의 레퍼런스 이미지와 다양한 프롬프트가 주어졌을 때의 생성된 이미지를 보여준다.


이미지 기반 이미지 생성(ControlNet)
저자는 ControlNet(Canny)를 적용한 실험 결과도 공유하였다. Source Image의 공간적인 요소를 대부분 수용하면서 Style Ref의 스타일을 매우 적절하게 적용한 결과를 볼 수 있다.

지난 연구들과의 결과 비교
저자는 이전에 공개된 모델들인 StyleAlign, Swapping Self-Attention, B-LoRA, original IP-Adapter(weight tuning)과의 생성 결과를 비교하였다. (B-LoRA는 저자가 직접 official 학습 환경을 적용하며 단일 레퍼런스 스타일 이미지에 대한 학습을 하였다.)

Ablation Study
임베딩 상에서 콘텐츠 정보를 빼는 것에 대한 효과 검증

각 전략 별 효과 검증




