
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- llama-4-scout-17b-16e-instruct
- vLLM
- CPT
- langchain
- ViT
- Lora
- ubuntu
- gemma2
- glibcxx
- Fine-tuning
- nccl
- gemma-3
- instruction tuning
- transformer
- gemma-3-27b-it
- PEFT
- multi-gpu
- prompt
- llama-4
- sfttrainer
- diffusion
- Gemma
- Text-to-Image
- error: mkl-service + intel(r)
- llm
- domain-adapted pre-training
- tensor-parallel
- lora+
- backbone
- Mac
- Today
- Total
꾸준하게
[논문리뷰] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE 본문
[논문리뷰] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
yeonsikc 2024. 6. 13. 22:55
ICLR 2021 (Oral) paper code
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby
Google Research, Brain Team
22 Oct 2020 (v1), 3 Jun 2021 (v2)
Abstract
주로 CNN을 이용해서 Vision Task를 해결하던 중 처음으로 Transformer를 이용한 논문이다. 본 논문에서는 이미지를 패치화 후 시퀀스화하여 입력으로 사용하였으며 이는 이미지 분류 태스크에서 높은 성능을 달성할 수 있었다. 대용량 데이터로 pre-train 후 다양한 중소형 해상도의 밴치마크에서는 연산량을 더 적게 가지면서도 SOTA를 달성하였다.
Method
전체적인 모델 디자인은 오리지널 Transformer를 최대한 따르는 방향으로 하였다. 저자는 이러한 의도적으로 간단한 설정의 장점은 확장 가능한 NLP Transformer 아키텍쳐와 효율적인 구현을 거의 즉시 사용할 수 있기 때문이라고 언급하였다.

Vision Transformer (ViT)
위 그림은 ViT의 전체 Overview이다. standard Transformer처럼 1D sequence를 받는데 이미지는 2D이기 때문에 변환 과정이 필요하다. 이미지
BERT에서의 class 토큰과 마찬가지로 저자도 학습 가능한 class 토큰 패치
패치 임베딩이 포지션 정보를 유지할 수 있도록 포지션 임베딩도 추가된다. 저자는 2D-aware 포지션 임베딩을 사용하였을 때 큰 효과를 느끼지 않아, 학습 가능한 표준 1D 포지션 임베딩을 사용하였다고 한다(Appendix D.4 참고). 임베딩 벡터의 결과 시퀀스는 인코더의 입력으로 사용된다.
Transformer Encoder는 multiheaded self-attention(MSA, Appendix A)과 MLP blocks(Eq. 2, 3)의 구성으로 이루어져있다. 매 블록 전에는 LayerNorm(LN)이 적용되어지고, 매 블록 후에는 Residual Connection이 연결된다. MLP에는 GELU non-linearity를 포함하는 2개의 레이어로 구성된다.
Inductive bias.
저자는 ViT가 이미지에 특화된 inductive bias가 CNN보다 적을거라고 언급한다. CNN은 2차원상에서 연결되어있는 지역적 구조를 갖고 translation equivariance 성질을 갖고 있지만, ViT는 오직 MLP layer에서만 이러한 특성들을 갖고있다. 2차원 구조는 이미지를 패치화 할 때나 포지션 임베딩을 적용할 때에만 사용된다. 그 외에, 초기화 시 위치 임베딩은 패치의 2D 위치에 대한 정보가 없으며 패치 간의 모든 공간 관계를 처음부터 학습해야 한다.
Inductive bias : 모델의 구조적 특성상 해당 데이터에 대해 기본적인 성능을 보일 수 있는 정도
Translation equivariance : 입력의 변화에 무관한 결과를 보임 (e.g. 이미지에서 고양이 위치가 바뀌어도 CNN 특성상 결과에 영향을 끼치지 않음)
위 설명은 간단히 나타낸 설명으로, 자세히 알기 위해서는 추가적인 구글링을 추천한다.
Hybrid Architecture.
원시 이미지 패치 대신 CNN으로 부터 추출된 feature map을 입력 시퀀스로 사용할 수도 있다. 이 하이브리드 모델은 위 'Eq. 1'에서
Fine-tuning and Higher Resolution
일반적으로 저자는 large dataset에 대해 ViT를 pre-train하였고 작은 downstream task를 위해 fine-tuning을 하였다고 한다. 이를 위해 pre-trained prediction head를 제거하고 zero-initailized
Experiments
저자는 ResNet, ViT, Vit(hybrid) 모델에 대해 실험을 진행하였으며, 각 모델의 데이터 요구조건을 이해하기 위해 다양한 사이즈와 많은 밴치마크 태스크에 대해 평가하였다. 사전학습 모델의 계산 비용을 고려할 때, ViT는 매우 우수한 성능을 발휘하여 대부분의 인식 벤치마크에서 더 낮은 사전학습 비용으로 SOTA를 달성하였다. 마지막으로, self-supervision을 이용한 작은 실험에서 self-supervised ViT가 미래에 대한 가능성을 가지고 있다고 저자는 언급하였다.
Setup
Datasets.
- ImageNet-1k, 1.3M images
- ImageNet-21k, 14M images
- JFT-18k, 303M high-resolution images
- 데이터 전처리는 "Big transfer (BiT): General visual representation learning" 논문의 내용을 따름
Model Variants.

저자는 BERT에 사용되었던 configurations을 이용하여 "Base", "Large"를 구성하였으며 추가적으로 "Huge" config를 추가적으로 구성하였다(ViT-L/16 : Large &
실험에서 CNN의 베이스라인으로 ResNet을 사용하였지만, BatchNorm을 GroupNorm으로 대체하였으며 standardized convolution을 사용하였다. 이 수정사항은 전이를 더 잘하게 하며 저자는 이를 ResNet(BiT)라고 칭하였다. hybrid 모델에서는 픽셀 크기가 1이 되는 패치사이즈를 갖는 중간 feature map을 ViT에 입력으로 사용한다. 달라지는 시퀀스 길이에 대한 실험을 위해, (i) regular ResNet50의 stage 4의 출력을 사용하거나, (ii) stage 4를 제거하고 stage 3에 같은 수의 레이어를 놓으며 확장된 이 stage 3의 출력값을 사용하였다. 옵션 (ii)의 경우, 4배 더 긴 시퀀스 길이를 갖게되며 ViT모델이 더 비싸진다.
Training & Fine-tuning.
아래 사항들은 ResNet을 포함한 모든 모델에 적용되는 Hyper parameter이다.
- Optimizer : Adam (
β1=0.9,β2=0.999 - Batch size : 4096
- Weight decay : 0.1
- linear learning rate warmup and decay
- For fine-tuning : SGD with momentum, batch size 512
- Image resolution : 512 for ViT-L/16 and 518 for ViT-H/14
Comparison to State of the Art

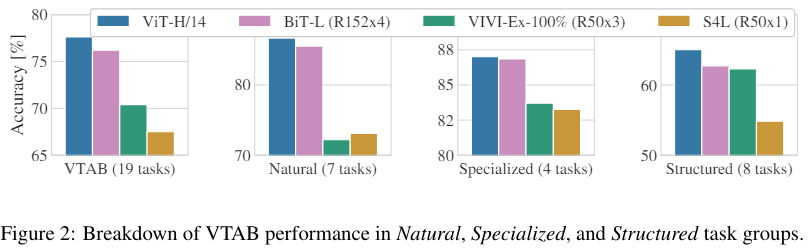
저자는 먼저 큰 모델(ViT-L/16 , ViT-H/14)을 CNN계열의 SOTA 모델인 ResNet을 사용한 BiT 그리고, EfficientNet에 Noisy Student를 접목한 모델과 비교하였다. 결과는 위 테이블에서 볼 수 있다.
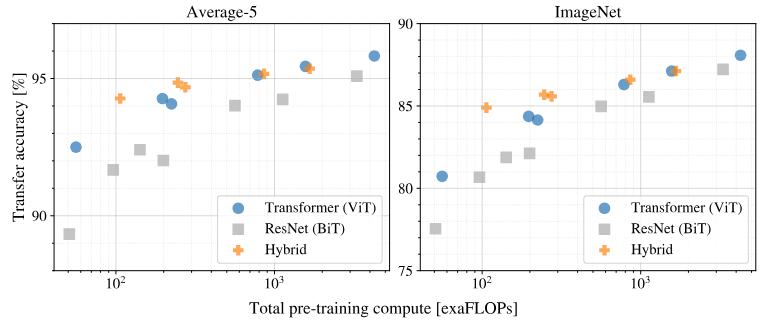
Pre-training Data Requirements

ViT는 대용량 사전학습데이터셋인 JFT-300M에서 좋은 성능을 보였다. 하지만 ViT는 ResNet보다 Vision에 더 적은 inductive bias를 갖기 때문에, 저자는 데이터셋의 규모가 얼마나 중요한지 다음 두 가지 실험을 진행하였다.
첫 번째 실험 : 데이터 셋에 따른 실험
- dataset : ImageNet-1k, ImageNet-21k, JFT-300M
- hyper parameters : weight decay, dropout, label smoothing
두 번째 실험 : JFT 데이터 셋의 subset 규모 변화에 따른 실험
두 실험에 대한 결과는 위 그래프에서 볼 수 있다.
Inspecting Vision Transformer
저자는 ViT의 내부 표현이 어떻게 진행이 되는지 분석해보았다. 아래 그림에서 첫번째 그림은 ViT-L/32의 첫 linear embedding의 필터를 나타낸 것이다. 두 번째 그림은 ViT-L/32의 포지션 임베딩의 유사도를 나타낸 것이다. 세 번째 그림은 헤드 및 네트워크 깊이 별 attention 영역의 크기를 나타내고, 각 점은 한 레이어에 잇는 16개의 헤드 중 하나의 이미지에 대한 mean attention distance를 나타낸다 (부록 D. 7 참고) . 네 번째 그림은 입력 이미지에 따른 Attention 영역을 보여준다.


ViT의 첫 번째 레이어는 평평한 패치를 저차원 공간에 선형적으로 투영한다. (Eq. 1) 투영 후, 학습된 위치 임베딩이 패치 표현에 추가된다. 위 그림에서 두 번째 그림은, 모델이 이미지 내 거리를 포지션 임베딩의 유사성으로 인코딩하는 방법을 학습한 것을 보여준다. 즉, 가까운 패치는 더 유사한 포지션 임베딩을 갖는 경향이 있다. 또한 행-열 구조가 나타나며, 같은 행/열에 있는 패치는 비슷한 임베딩을 갖는다. 마지막으로 큰 그리드에서는 때때로 정현파 구조가 나타난다(부록 D).
위 두번째 그림을 보면, 일부 헤드는 이미 가장 낮은 층에 있는 이미지에 대부분 주의를 기울이는것으로 나타났는데, 이는 모델에서 정보를 전체적으로 통합하는 능력이 실제로 사용된다는 것을 보여준다.



