
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- prompt
- Text-to-Image
- ViT
- Lora
- langchain
- instruction tuning
- gemma-3
- aimv2
- torch._C._cuda_getDeviceCount()
- Gemma
- Mac
- Fine-tuning
- gemma-3-27b-it
- openAI
- diffusion
- ubuntu
- Python
- CPT
- backbone
- llama-4
- PEFT
- nccl
- tensor-parallel
- transformer
- glibcxx
- llm
- multi-gpu
- llama-4-scout-17b-16e-instruct
- sfttrainer
- vLLM
- Today
- Total
꾸준하게
[논문리뷰] LoRA+ : Efficient Low Rank Adaptation of Large Models 본문
arXiv paper code
Soufiane Hayou, Nikhil Ghosh, Bin Yu
UC Berkeley
19 Feb 2024
들어가기에 앞서..
본 논문은 LoRA 논문의 확장 연구로서 기본적인 LoRA 개념은 다루지 않을 예정입니다. 혹시 LoRA를 아직 보지 않으신 분은 이 곳을 통해 먼저 개념을 익히고 들어오시기를 추천드립니다.
Abstract
본 논문에서는 LoRA에서 Matrix B, A에 같은 Learning rate를 사용하는 것은 효율적이 않다고 주장하였다. 그러면서 간단한 방법으로 learning rate를 다르게 설정하는 LoRA+를 제안하였다. 이는 같은 컴퓨팅 자원에서 LoRA 대비 1~2%pt의 성능 향상과 약 2배까지의 속도 향상이 가능하다고 주장한다.
1. Introduction
이전의 LoRA 논문의 경우, rank의 하한선만 언급할 뿐 학습 속도(lr)는 1e-4로 고정된 값을 사용했다고 지적하였다.
2. Related work
QLoRA는 LoRA를 weight를 최소 4bit까지 절감하는 Quantization 버전이며 단일 GPU에서 LLaMA-65B까지도 학습할 있다.
LoftQ는 양자화를 통한 LoRA 학습의 연산을 효율화하기 위해 제안 된 것으로 더 나은 초기값을 설정하는 방법이다.
VeRA는
하지만 위 연구들 모두에서 Learning rate에 대한 언급은 없었다.
Contributions

본 논문에서는 신경망의 scaling 이론을 통해 learning rate를 설정하는 가이드라인을 제세한다고 한다. 구체적으로, 신경망의 폭/깊이를 무한대로 가정하고 하이퍼 파라미터(learning rate, initialization variance 등)에 따른 극한의 동작이 어떻게 변화하는지 이해한다. 이후, 원하는 목표(예 : feature learning)를 달성하기 위해 하이퍼파라미터의 원칙적인 선택을 도출한다.
구체적으로, LoRA+는 위 그림과 같이 A모듈과 B모듈의 학습 속도(lr)를 다르게 설정하는 방법이다. 매우 간단한 방법이지만 이에 대한 성능은 다양한 언어 모델을 통해서 결과로서 검증이 되었다.
Setup and definitions
Scaling of Neural Networks
일반적으로, 모델 폭(embedding dim)이 커진다면 초기값 설정 방식과 학습을 조정하여 효율적인 학습을 해야하는것으로 알려져 있다. 예를들어, initilization weights의 분산은 모델 폭 'n'이 커지면 large pre-activations을 방지하고자
3. An intuitive analysis of LoRA
LoRA의 행렬 A와 B는 Transpose 모양을 하고있으며(위 그림을 보면 이해에 도움됨) 두 행렬에 대해 learning rate를 다르게 설정해야하는지에 대해 질문을 남길 수 있다. 실제로 대부분의 SOTA 모델은 모델의 폭(embedding dim)이 너무 크다. 따라서 저자는 폭이
How should we set the learning rates of LoRA modules A and B as model width n → ∞ ?
간단한 Linear model을 통해 무한한 폭의 fine-tuning 역학에 대해 분석하고 폭에 따라 '최적'의 학습 속도에 대해 추론한다.
3-1. LoRA with a toy model
위 수식은 입력크기 n을 받으면 출력크기 1로 출력하는 간단한 Linear model이며 이때 LoRA의 Rank r=1이다.
Initialization
일반적으로라면 다음과 같이 Gaussian initialization으로 weight를 초기화한다.
다만 LoRA에서는 첫 iteration에서
결과적으로 다음 두 가지 방법을 선택할 수 있게된다.
Learning rate
위 수식은
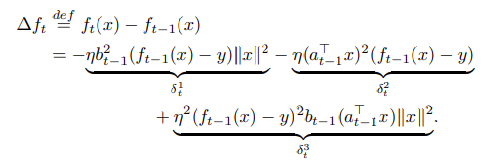
위 수식의 우항인 세 term은 각각
n이 커짐에 따라 바랍직한 값은
결론적으로, n이 무한에 가까울 때(클 때)
실험 결과, LoRA와 같은 컴퓨팅 자원에서 1~2%의 성능 향상을 기록하였으며 학습 속도는 2배가량 높아졌다고 한다.
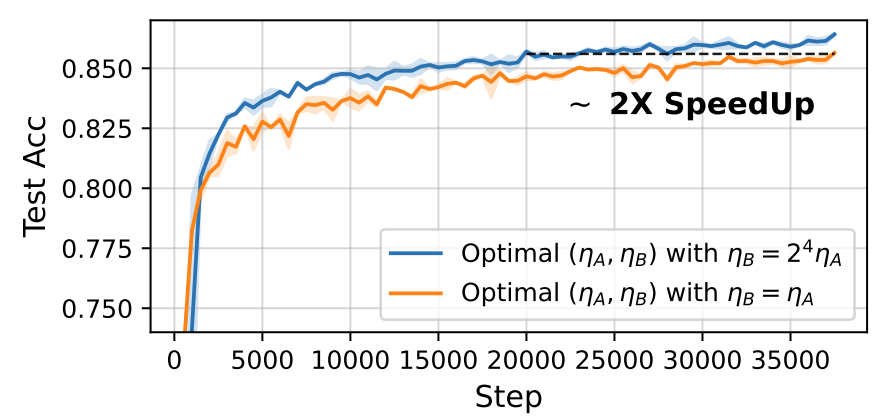
본 논문에서 제안하는 학습 트릭이 너무 간단하여 논문 또한 쉽기 편할 줄 알았는데 생각보다 분석한 내용이 많아서 의외였다. 다음에 관련 대회에 참가할 기회가 생기면 QLoRA와 DoRA, LoRA+의 이점을 합쳐 Fine-tuning을 해볼 계획이다.


