
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- PEFT
- glibcxx
- ubuntu
- instruction tuning
- instruct-pt
- error: mkl-service + intel(r)
- instruction tuning (it)
- lora+
- backbone
- instruct pre-training
- llm tuning
- langchain
- Mac
- CPT
- Text-to-Image
- llm
- prompt
- ViT
- full fine-tuning (fft)
- sfttrainer
- Lora
- diffusion
- domain-adapted pre-training
- Fine-tuning
- cross-document attention
- continual pre-training
- gemma2
- continued pre-training
- transformer
- continued pre-train (cpt)
- Today
- Total
꾸준하게
[논문리뷰] Instruction Pre-Training: Language Models are Supervised Multitask Learners 본문
[논문리뷰] Instruction Pre-Training: Language Models are Supervised Multitask Learners
yeonsikc 2024. 10. 1. 18:15ICLR 2024 Conference [github] [paper]
Daixuan Cheng, Yuxian Gu, Shaohan Huang, Junyu Bi, Minlie Huang, Furu Wei
Microsoft Research | Tsinghua University
Submitted on 6 Jun 2024
Abstract
LM 모델들이 비지도학습만으로 좋은 성능을 내고있으며, 사후 학습으로 지도학습(SFT, Instruction Tuning)을 통해 생성 능력을 더 높힐 수 있다. 저자는 Instruction Pre-Training이라는 supervised multitask pre-training을 제안하였는데 이는, instruction-response 페어 형태의 거대한 raw corpora를 통해 LM을 pre-train하는 방법론이다. 저자는 40가지가 넘는 다양한 태스크에 200M규모의 페어 데이터 셋을 구축하여 성능을 검증하였다. 결과적으로 Llama-3-8B 모델이 Llama-3-70B 성능을 능가하였다고 한다.
Instroduction
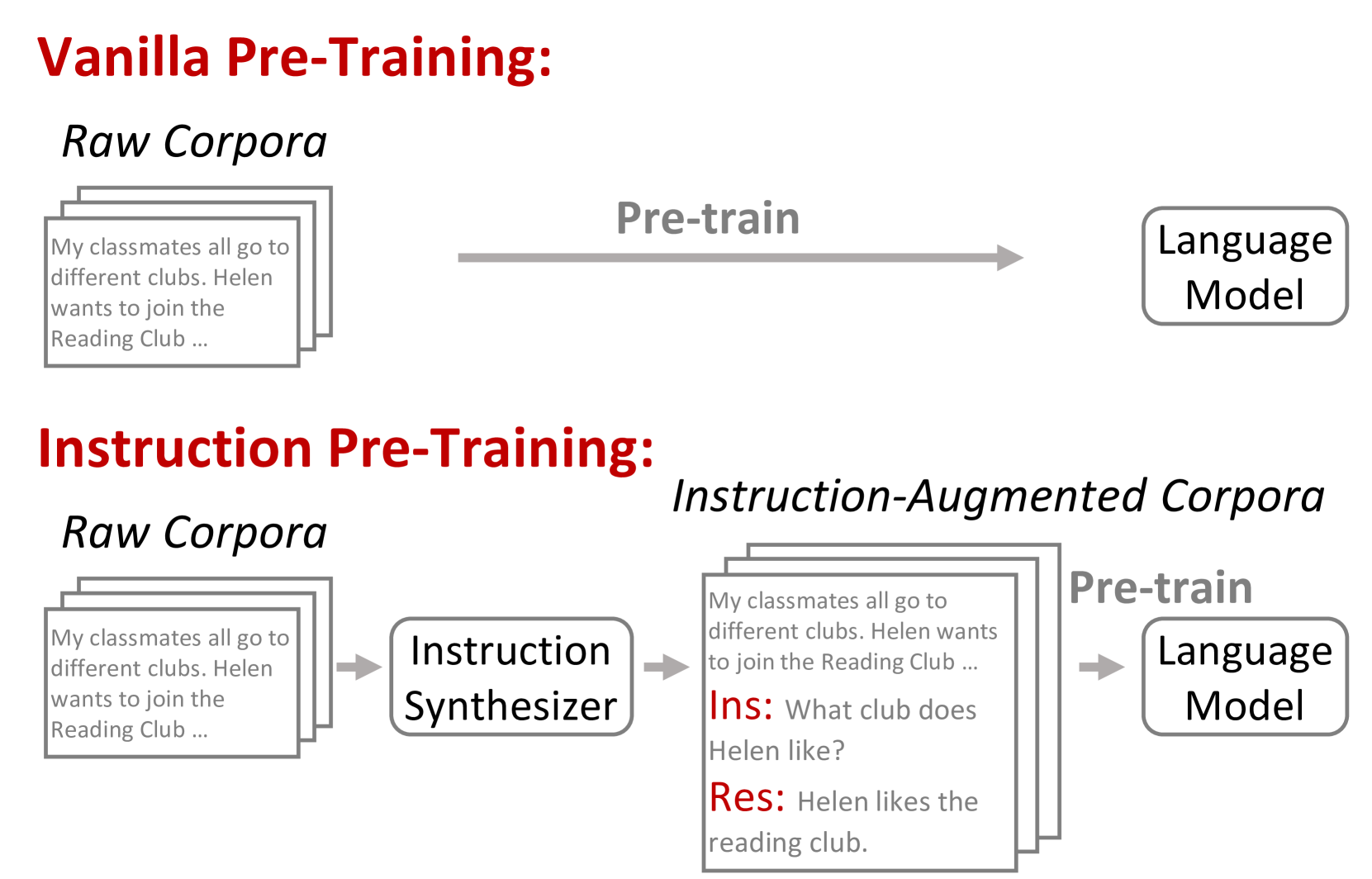
위 Fig. 1.은 Vanilla Pre-training과 달리 임의의 Instruction 생성모델을 사용하여 Raw Corpora에 대해 Instruction과 Response을 생성하게되고, 이를 Language Model 사전학습을 위해 사용된다. 이로써 Vanila Pre-Train 보다 학습 수렴 속도가 1.x배 빨라지고 별도의 Instruction Tuning 단계를 거치지 않아도 다양한 태스크에 대해 곧바로 사용할 수 있다.
Instruction 생성 모델을 만들기 위해 기존에 존재하던 광범위한 데이터셋들을 instruction-response 페어와 raw text 형태로 변환시켰다. 그 다음, raw text에서 instruction-response 페어를 생성하도록 언어 모델을 fine-tuning하였다. 매우 다양한 tuning data 덕에 모델은 한 번도 보지 못했던(unseen) data에 대해서도 잘 생성 할 수 있었다고 한다. 사용한 모델은 비용 효율을 고려하여 7B params 정도의 오픈소스 SLM을 사용하였다고 한다.
저자는 제안한 방법의 효과를 확인하기 위해 Pre-train from scratch와 Domain-adaptive continual pre-traiing에서 실험을 진행하였다. 결과적으로 Pre-train from scratch에서는 100B token으로 학습된 500M규모의 모델이 300B token으로 학습된 1B 모델의 성능을 내었으며 추가적인 instruction-tuning 과정을 통해 더욱 이점을 얻었다. Domain-adaptive continual pre-traiing에서는 금융 분야와 생물학 분야에 대해 실험하였으며 Llama3-8B 모델이 Llama3-70B 수준의 성능을 보였다고 한다.
Contributions
- supervised multitask pre-training 방법론인 Instruction Pre-Training을 제안하였으며, 광범위한 실험을 통해 이의 효과를 입증하였다.
- 다양한 raw corpora에 근거하여 다양한 instruction-response 페어를 확장할 수 있는 instruction synthesizer을 개발하였다.
- Instruction 생성기와 생성 데이터를 종합적으로 분석하여 제안한 방법의 성공을 향한 핵심 요인을 밝혔다.

Instruction Pre-Training

Instruction Synthesizer
위 Fig. 3.은 Instruction 생성모델의 학습과 추론 과정을 보다 자세하게 설명한 그림이다. 학습 과정에서는 하나의 데이터셋으로 부터 여러 one-shot example을 concat하여 학습에 사용된다. 이때, loss는 오직 Instruction-response token에서만 계산된다. 추론 과정에서는 multi-round inference 방식으로 작동하는데, $\text{Round}_i$는 $\text{Round}_(i-1)$의 sequence(raw text + instruction + response pair)를 기반으로 하여 새로운 instruction-response 페어를 생성한다. (학습과정에서도 one-shot example을 concat하여 여러 example을 한 번에 볼 수 있게 했는데, 이는 결국 이전 instruction-response를 보고 다양한 instruction-response pair를 생성하도록 유도한 것으로 판단된다.)
LM Pre-Training
데이터 셋 구성 외의 모든 설정은 Vanilla Pre-Training과 같게한다. 즉, Instruction-response token들 외에 raw text 부분도 loss를 계산한다.
General Pre-Training Form Scratch


일반적인 pre-training에는 처음부터 많은 양의 데이터가 필요하기 때문에 원시 코퍼스의 일부만 명령어 증강 코퍼스로 변환하고 나머지는 그대로 둔다(computing cost 때문일 것이라 추정). 또한, 작업의 다양성을 높이기 위해 Instruction 생성모델을 미세 조정하기 위한 데이터와 코퍼스를 혼합하였다.
Domain-Adaptive Continual Pre-Training
From Scratch보다 필요 데이터 수가 훨씬 더 적기 때문에 모든 데이터에 대해 Instruction-response를 생성하였다. 그리고 Cheng. 논문(본 저자의 이전 논문)의 설정을 따라 general instruction을 섞었는데 이는 프롬프팅 능력의 이점을 갖기 위함이라고 하였다.(LiMA 논문도 참고하면 더 좋다.) 이떄, instructio synthesizer를 fine-tuning 할 때 사용되었던 general instruction collection들은 사용하지 않았다고 한다.
Experiment Settings
Instruction Synthesizer

- Base Model : Mistral-7B-v0.1
- \n\n 사용 : raw text, instruction, response 사이에 넣어줌
- <s>, </s> : 각 example 전/후에 삽입
- Inference 때에 raw text당 5개의 instruction-response pair 구성되며 각 pair당 약 52개의 토큰이 포함됨
General Pre-Training From Scratch
- 데이터 : RefinedWeb dataset (200M, 100B tokens)
- instruction-response 생성
* 전체 corpora의 20%(40M raw texts)만 instruction-response를 생성하였음
* 총 두 번의 Round를 시행하였음(첫 20M raw texts에 대해서는 첫 round를 진행하였고(raw text만 보고 생성), 나머지 20M raw texts에 대해서는 두 번째 round를 진행하였음(raw text + 첫 번째에서 생성한 instruction-response를 보고 생성)
- 생각보다 실험 환경에 대한 설명이 자세하게 되어있어 본 논문에서 찾아보길 권한다.
Domain-Adaptive Continual Pre-Training

- 모델 : Llama3-8B
- 데이터 : PubMed Abstracts (for biomedicine), financial news (for finance)
- 추론 단계는 총 3라운드 시행
- 모든 데이터에 대해 페어 생성
- 각 라운드에서는 전체 raw text 중 1/3을 시행하였으며 나머지 두 라운드도 같은 방식으로 진행되었음(1라운드 결과 -> 2라운드 결과 -> 3라운드 결과, autoregressive 방식) -> Table 13, 14 참고
- general instructions 데이터와 1:1 비율로 함께 학습 진행
- 학습 하이퍼 파라미터는 위 표 참고
Results
- 성능이 어쩌면 당연히(?) 우수하게 나온다!
- 본래 LLM은 Pre-train 이후 Instruction-tuning을 통해 사용자 지시에 적합한 답변을 하도록 추가 학습을 진행한다.
- Instruct-PT는 Pre-train과 Instruction-tuning을 하나의 프로세스(사실 Instruction Synthesize를 거치기 때문에 전체로 보면 2내지 3프로세스(instruction synthesize 학습까지 고려하면 ..))로 학습하였기에 Instruction-tuning 모델과의 비교를 하지 않은 것이 아쉬움에 남는다.
General Pre-Training Form Scratch
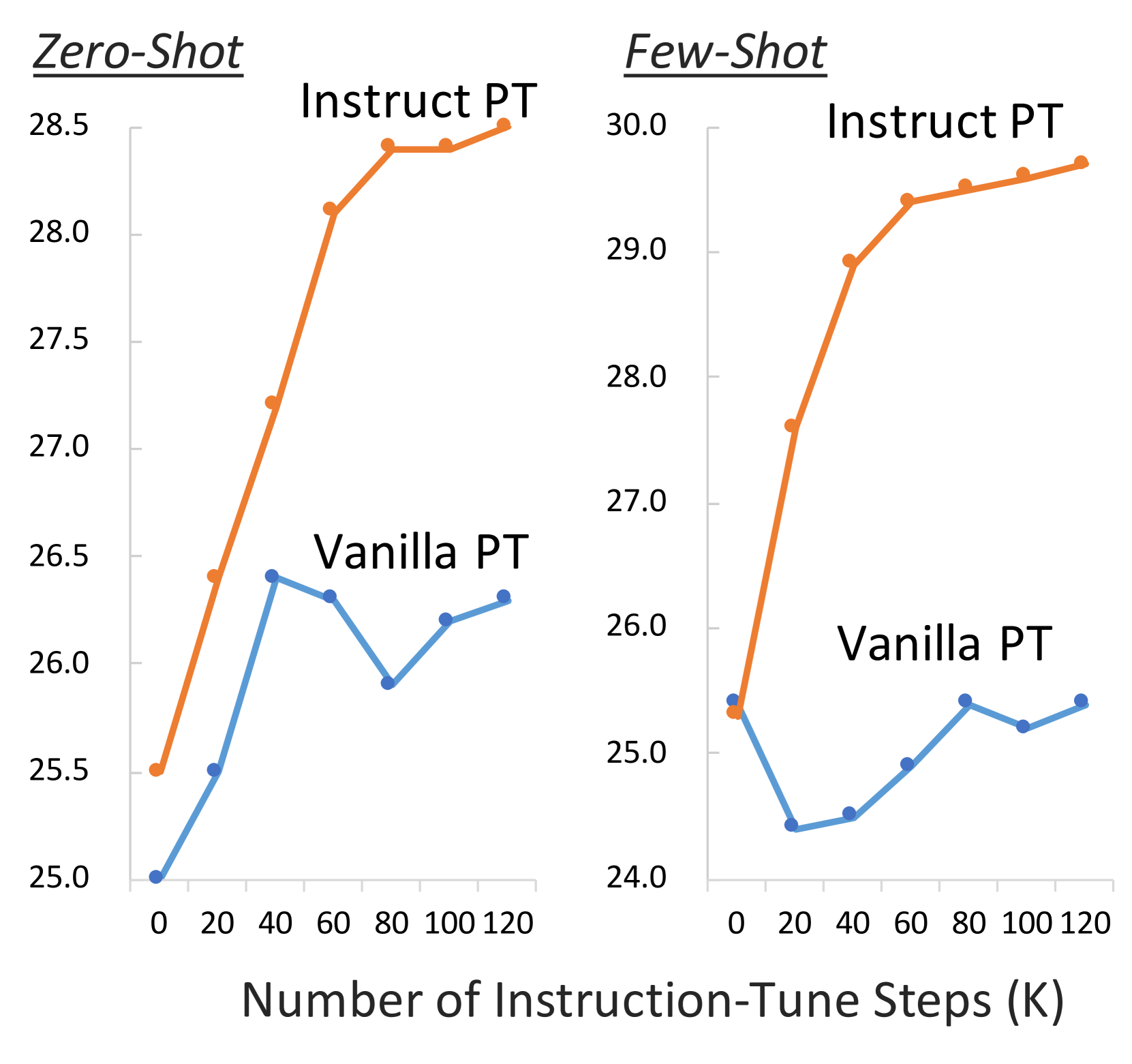
Domain-Adaptive Continual Pre-Training

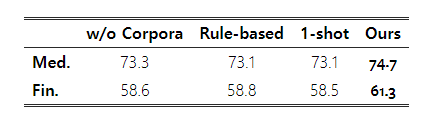
Analysis
Instruction Synthesizer
Instruction Synthesizer에 대해 multi-task tuning을 한 목적이 unseen 데이터에 대해서도 좋은 성능을 내기 위함이었으므로 저자는 seen 데이터와 unseen 데이터의 성능평가를 구분하여 진행하였다. 아래 표는 다양한 벤치마크에 대한 평가로, 논문 Appendix A에 자세한 데이터 리스트가 나와있다. Accuracy는 정답과 모델이 예측한 값 간의 F1-similarity를 나타내고, Quality는 생성된 Instruction-response 페어와 기존의 정답 instruction-response 페어간의 F1 similarity를 나타낸다.


Instruction-Augmented Corpora
문맥 관련성, 응답 정확도, 과제 다양성 측면에서 Instruction-Augmented Corpora를 분석하였다. 증강된 말뭉치에서 500개의 Instruction 증강 텍스트를 샘플링하고 GPT-4를 사용하여 생성된 Instruction-response pair를 평가하였다. 구체적으로, 생성된 Instruction이 raw text의 context과 관련이 있는지(맥락 관련성), Instruction과 Context에 따라 응답이 정확한지(응답 정확도), 사전 정의된 task category 목록을 사용하여 생성된 instruction-response pair를 분류(과제 다양성)하였다. 전체적으로 품질이 좋고 다양하며 관련성이 높은 것으로 나타났다.





